Can AI Really Build Software From Scratch? What ProgramBench Reveals
ProgramBench is the first benchmark that tests whether AI can design and build complete software systems — not just write code snippets. The results are more humbling than the hype suggests.
Can AI Really Build Software From Scratch? What ProgramBench Reveals
Every week there's a new demo. Someone prompts an AI, it generates a full app, and the caption says something like "software engineering is dead" or "this replaced my developer."
I've watched a lot of these demos. And I've noticed something: they almost always show the AI completing a narrow, well-defined task. Build a todo app. Add a login page. Fix this bug. Write a REST endpoint.
That's useful. But it's not what software engineering actually is.
Real software engineering is the work that happens before you write a single line of code. What should this system do? How should it be structured? What trade-offs make sense? How do the pieces fit together?
A new benchmark called ProgramBench is the first rigorous attempt to test AI on that harder question — across 9 frontier models including Claude, GPT, and Gemini. And the results reveal a gap between the AI coding hype and the current reality that every builder, developer, and technical founder should understand.
Source: Yang et al., "ProgramBench: Can Language Models Rebuild Programs From Scratch?", arXiv:2605.03546 (2026). Read the paper →
What ProgramBench Actually Tests
Most AI coding benchmarks test the same thing: give the model a function signature or a broken piece of code, and see if it can complete or fix it. Those are useful tests. But they measure AI as a code writer, not as a software designer.
ProgramBench flips the setup entirely.
Instead of handing the model source code to work with, it gives the model:
- A compiled, running program — a black box it can interact with
- Documentation — describing what the program is supposed to do
- No source code — at all
The task: recreate the entire codebase from scratch so that the new program behaves exactly like the original. The benchmark covers 200 tasks ranging from simple CLI tools all the way to major real-world projects like FFmpeg and SQLite.
Compiled binary + Docs
↓
AI Agent (no source code)
↓
New source code + build script
↓
Behavioral equivalence tests (agent-driven fuzzing)The benchmark doesn't care if the AI's code looks like the original. It only cares whether it works like the original — tested through agent-driven fuzzing that generates behavioral tests without prescribing implementation structure. That distinction matters, because it forces real engineering judgment, not pattern matching.
Why This Is the Right Question to Be Asking in 2026
The question "can AI write code?" has been answered. Yes, it can. Extremely well in many cases.
The question the industry needs to answer now is different: can AI engineer software?
Writing code is local. You have a context — a function, a file, a module — and you produce output within that context. AI is genuinely excellent at this.
Engineering software is global. You're making decisions that affect the entire system: how data flows, where state lives, how components communicate, what happens when requirements change. These decisions compound. A bad architectural choice made at the start creates friction for every feature that comes after.
ProgramBench tests the second one. And that's why the results are worth paying attention to.
The Results: Every Model Scored Zero
Here's the number that stops most people cold.
Not a single model fully resolved any task. Zero out of nine. Zero out of 200.
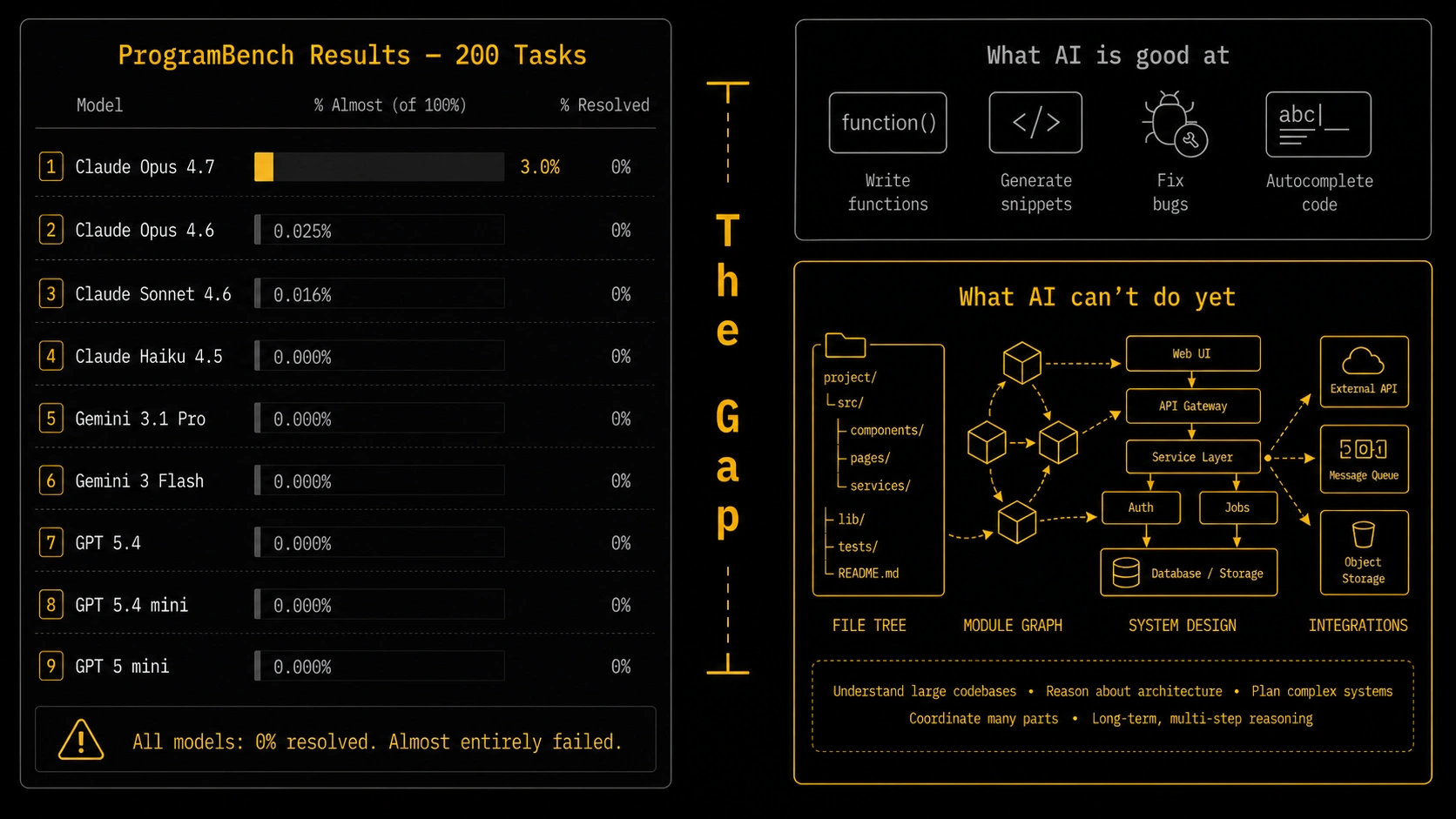
That's not cherry-picked. That's the result across every frontier model the researchers tested — Claude Opus 4.7, Claude Opus 4.6, Claude Sonnet 4.6, Claude Haiku 4.5, Gemini 3.1 Pro, Gemini 3 Flash, GPT 5.4, GPT 5.4 mini, and GPT 5 mini.
The table below shows the full results. "% Resolved" means fully passing all behavioral tests. "% Almost" means passing ≥95% of tests — the closest any model came to a real solution.
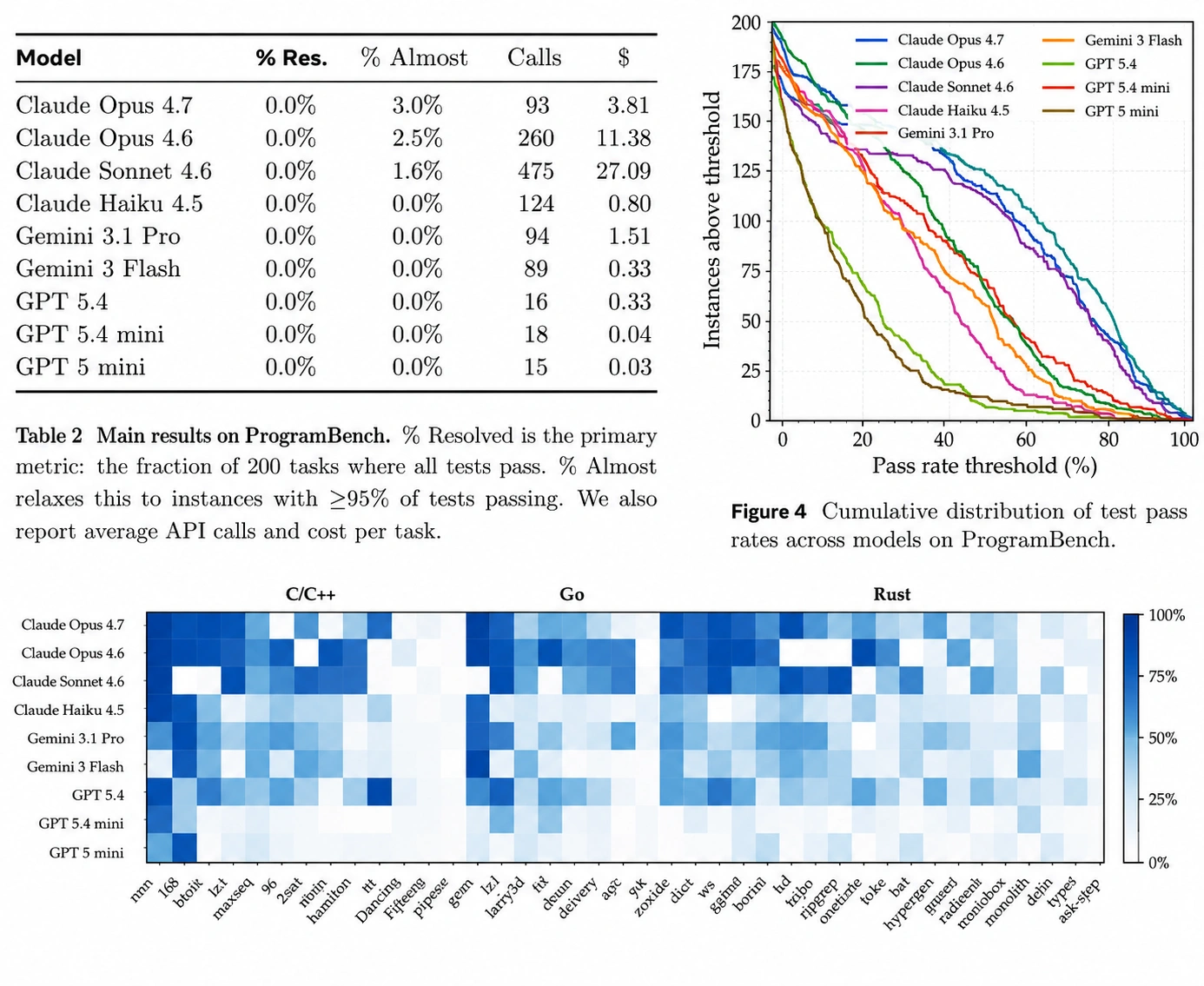
| Model | % Resolved | % Almost (≥95% tests) | Cost per task |
|---|---|---|---|
| Claude Opus 4.7 | 0.0% | 3.0% | $3.81 |
| Claude Opus 4.6 | 0.0% | 2.5% | $11.38 |
| Claude Sonnet 4.6 | 0.0% | 1.6% | $27.09 |
| Claude Haiku 4.5 | 0.0% | 0.0% | $0.80 |
| Gemini 3.1 Pro | 0.0% | 0.0% | $1.51 |
| Gemini 3 Flash | 0.0% | 0.0% | $0.33 |
| GPT 5.4 | 0.0% | 0.0% | $0.33 |
| GPT 5.4 mini | 0.0% | 0.0% | $0.04 |
| GPT 5 mini | 0.0% | 0.0% | $0.03 |
Source: ProgramBench paper, Table 2. "% Almost" = tasks where ≥95% of behavioral tests pass.
Claude Opus 4.7 came closest — 3% of tasks at the "almost" threshold. Every other model either scored lower or hit zero. The best model in the world on standard coding benchmarks couldn't fully rebuild a single program when given only its binary and documentation.
That's not a failure of one model. That's a signal about where the frontier actually is.
How AI Models Actually Behave Under This Test
The paper documents specific patterns in how models approach these tasks that are worth understanding if you build with AI regularly.
They collapse complexity into single files.
Instead of designing modular architectures — separate concerns, clean interfaces, organized file trees — most models generated single-file or minimal-structure solutions. 67% of model solutions used shallower directory structures than the original programs. It's rational from the model's perspective: a flat structure requires fewer long-range decisions. But it's not how you'd structure anything you'd maintain.
They write dramatically less code.
The median model solution was 1,173 lines of code. The median original program was 3,068 lines. 85% of model solutions fell below that parity line. And within that smaller codebase, models wrote only 10–29% as many functions as the original — compensating with functions that were 1.08× to 1.62× longer.
Fewer functions, longer bodies. Less structure, more length. That's the signature of code that works locally but doesn't scale.
They don't iterate the way humans do.
Real software development is iterative. You write something, test it, realize you made a wrong assumption, backtrack, and try again. The action counts in the paper reveal a striking split: Claude Sonnet 4.6 used a median of 868 commands per task — exploring, testing, refining. GPT 5.4 used just 17.
One model over-explores without resolving. The other under-explores and submits too early. Neither matches the measured, purposeful iteration of an experienced engineer.
They pick the wrong language half the time.
Models matched the reference program's language in only 50% of runs. When left to choose, they defaulted to Python (36%), Rust (25%), and Go (20%) — regardless of whether those were appropriate choices for the task.
What This Means If You're Building With AI Right Now
I want to be precise here because the wrong takeaway is "AI is overrated, ignore it." That's not what the data says.
What AI is genuinely excellent at:
- Writing specific functions given a clear spec
- Generating boilerplate and scaffolding for known patterns
- Implementing a feature within an existing, well-structured codebase
- Debugging local errors with clear context
- Rapid prototyping of UIs and simple flows
Where the gap is still significant:
- Deciding how to structure a new system from scratch
- Maintaining architectural consistency as a codebase grows
- Making trade-off decisions that affect the system globally
- Iterating on a design when requirements turn out to be more complex than expected
ProgramBench makes that second list measurable. The practical implication: AI works best when a human has already made the hard architectural decisions. Give it a well-defined component to build within a clear structure, and it performs impressively. Ask it to design and build a system end-to-end from nothing, and it will produce something that looks complete but isn't.
Why This Benchmark Is Harder to Game
There are a lot of AI coding benchmarks. Most of them have been quietly saturated — models train on similar distributions, scores climb, and the benchmark stops measuring what it was supposed to measure.
ProgramBench is harder to game because it tests behavioral equivalence, not code structure. You can't pass it by memorizing patterns from training data. The test inputs are generated fresh by agent-driven fuzzing against the original binary. You have to actually solve the problem.
That makes it a more honest signal about real capability.
It also reframes the question the industry should be asking. Instead of "how many HumanEval problems can this model solve," the question becomes: "can this model do what a junior engineer can do unsupervised?" ProgramBench says: not yet, not reliably.
That's more productive. Because it points to specific, addressable gaps — iteration, architecture, global consistency — rather than just a percentage on a leaderboard.
The 0% Number in Context
Zero out of 200 sounds discouraging. But the right frame is what it tells you about the next five years.
Two years ago, the answer to "can AI write code at all?" was "sometimes, poorly." Today, AI writes production-quality code for narrow, well-defined tasks routinely. The improvement over that period was real and significant.
ProgramBench gives researchers a concrete target for the next phase: not "generate more code" but "design better systems." Those require different capabilities — planning, global consistency, self-correction — that are active areas of research and will improve.
What ProgramBench reveals is where the frontier actually is. Not "AI can't code" — that battle is over. But "AI can't yet engineer" — and that's the next one.
Final Thoughts
The framing of "AI replaces developers" has always been imprecise. What the data — including ProgramBench — actually shows is more nuanced and more useful.
AI is an excellent implementation partner when the thinking has already been done. It handles the local, the repetitive, the well-specified. It struggles with the global, the ambiguous, the architectural. Those aren't the same job, and conflating them leads to disappointment in both directions.
The builders who get the most out of AI right now are the ones who use it to accelerate the parts it's good at, and keep their own hands on the parts it isn't.
Zero out of 200. Every model. The most honest number I've seen published about AI coding capability in a long time.
Source: Yang et al., "ProgramBench: Can Language Models Rebuild Programs From Scratch?", arXiv:2605.03546 (2026). Read the full paper →