Knowledge Graphs: Why Vectors Aren't Enough
I built a RAG system that passed every test I threw at it — until a real user asked one question that exposed everything vectors fundamentally can't do.
Knowledge Graphs: Why Vectors Aren't Enough
I'll tell you exactly when I realized vectors weren't enough.
I had built a RAG system over an internal company knowledge base — documentation, team structure, project records. I tested it extensively. It answered questions about products, processes, and policies well. I shipped it feeling pretty good about myself.
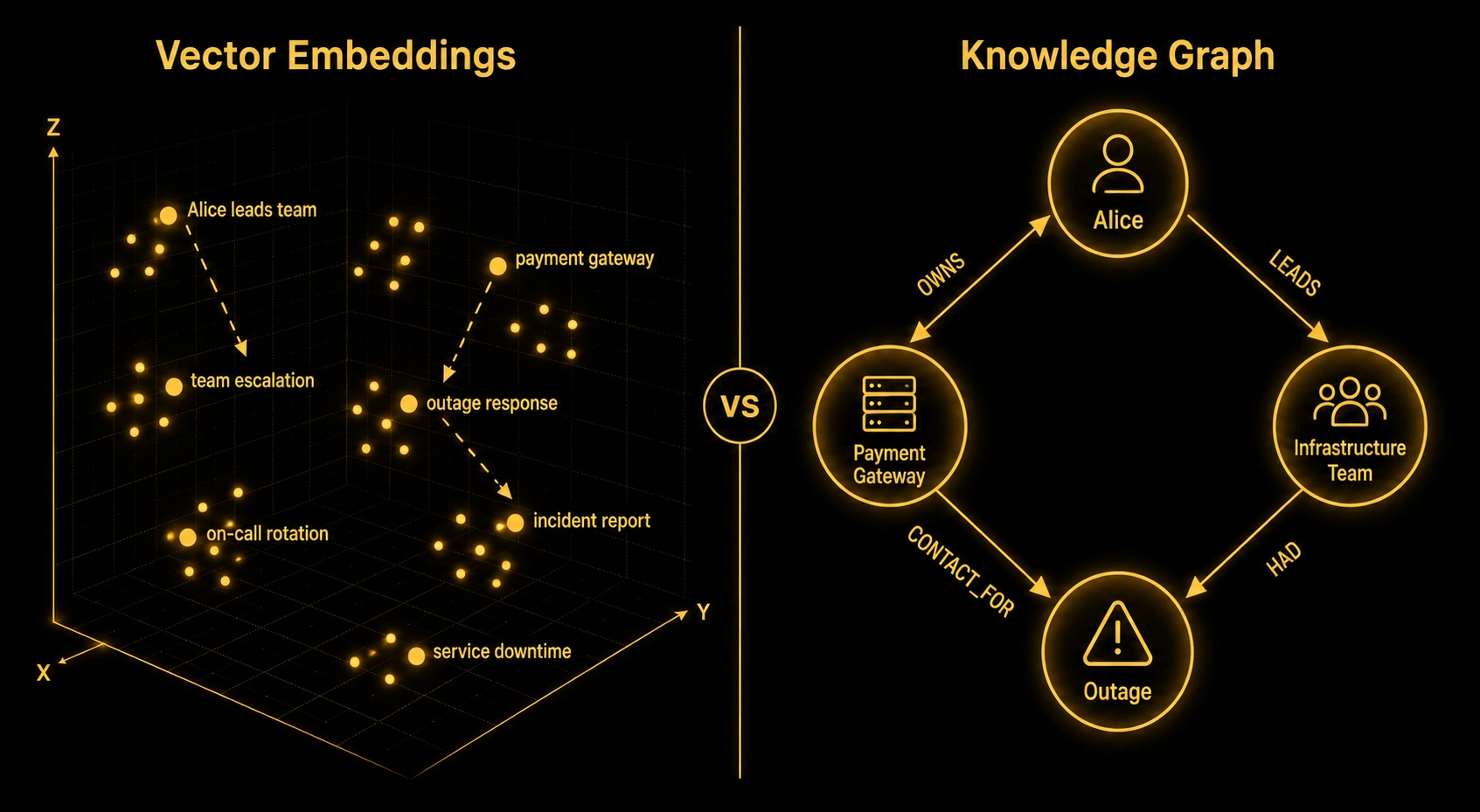
Then someone asked: "Which team is currently responsible for the payment gateway, and who do I talk to if it goes down?"
The system returned three chunks. One was about the payment gateway's architecture. One was about incident response in general. One was about a team called "Platform" from a document that was a year old.
None of it was useful. The actual answer required knowing that Platform was renamed to Infrastructure six months ago, that Infrastructure owns the payment gateway, and that Alice is the lead you'd contact. Three facts, none of them in a single document, all of them needing to be chained together.
I had a retrieval system that was great at finding similar text. I needed one that could reason about relationships. Those are fundamentally different problems.
What Vectors Actually Do (and Where They Silently Fail)
I want to be precise about this because most explanations are too vague.
A vector embedding takes a chunk of text and turns it into a list of numbers — typically 768 or 1536 of them — where the numbers encode semantic meaning. Chunks that mean similar things end up close together in that high-dimensional space. When you query, you embed the question and find the closest chunks. That's it.
This works shockingly well for a wide range of questions. It's one of the most impressive things I've seen in practice — the semantic understanding is genuinely good.
But here's what vectors can't do, and this took me longer than I'd like to admit to fully internalize:
They treat every chunk as an island. The embedding for "Alice leads the Infrastructure team" contains no structural connection to "Infrastructure owns the payment gateway." Those two chunks could be adjacent in your database or light-years apart — the vector store doesn't know or care.
This means that when you ask a question that requires connecting two facts from two different documents, vector search will find each fact in isolation but has no mechanism to combine them. You get two puzzle pieces, never the picture.
The failure mode is subtle and insidious because the system still returns something. It doesn't say "I can't answer this." It confidently returns the most similar chunks, which look relevant but don't actually answer the question. I watched people in my team assume the system was working correctly when it was systematically failing on relational questions.
What a Knowledge Graph Is, Practically Speaking
A knowledge graph is a database of entities and the relationships between them.
Instead of storing document chunks, you store facts like:
Alice --[LEADS]--> InfrastructureTeam
InfrastructureTeam --[RENAMED_FROM]--> PlatformTeam (as of 2025-06-01)
InfrastructureTeam --[OWNS]--> PaymentGateway
PaymentGateway --[CONTACT_FOR_INCIDENTS]--> AliceNow that question — "who do I contact if the payment gateway goes down?" — has a direct traversal path. You start at PaymentGateway, follow the CONTACT_FOR_INCIDENTS edge, and arrive at Alice. No semantic similarity required, no context window stuffing, just graph traversal.
The query looks like this in Cypher (Neo4j's query language):
MATCH (system:System {name: "PaymentGateway"})-[:CONTACT_FOR_INCIDENTS]->(person:Person)
RETURN person.name, person.emailThat's not fuzzy matching. That's a precise lookup. Which is exactly what you want for certain categories of questions.
The Entity Resolution Problem Nobody Warns You About
When I started actually building this, the first wall I hit was entity resolution.
You're extracting entities from documents using an LLM. Document A mentions "the Infrastructure team." Document B mentions "Infrastructure." Document C mentions "Infra team." Document D, written six months later, says "the Platform team (now called Infrastructure)."
These are all the same entity. Your graph doesn't know that unless you explicitly tell it. If you don't handle this, you end up with four separate nodes that should be one, and your traversal paths break because the edges you built from Document A's "Infrastructure team" don't connect to the edges from Document C's "Infra team."
I spent almost a week on entity resolution alone. The approach that worked best for me was:
- Extract entities with the LLM first
- Run a similarity check against existing entities in the graph before creating a new node
- If similarity is above a threshold (~0.85 cosine similarity on the entity name embedding), prompt the LLM to decide if they're the same entity
- Let a human review ambiguous cases before merging
It's slow. It's annoying. It's also completely necessary. Nobody's tutorial covers this, and it will break your graph silently if you skip it.
How Much It Actually Costs to Build a Graph with LLMs
I want to give you a real number because I wish I'd had one.
I was working with roughly 800 documents averaging about 1,500 words each. Using GPT-4o to extract entities and relationships from every chunk, running each chunk through the extraction prompt once:
- Total tokens: ~2.8 million input, ~400k output
- Cost at GPT-4o pricing: ~$12 for input,
$6 for output = **$18 to index 800 documents** - Time: about 4 hours with basic rate limit handling
That's not outrageous for a one-time indexing cost. The problem is what happens when documents change.
With vector RAG, updating a document means re-embedding the new version and replacing the old vectors. Cheap, fast, fully automated.
With a knowledge graph, updating a document means: extracting new entities and relationships, identifying which old entities/edges should be removed or updated, resolving the new entities against the existing graph, and re-running community detection if you're using GraphRAG. In practice, for a document that changed meaningfully, this takes 3–5x the time and cost of the initial indexing.
For a corpus that changes frequently — internal wikis, actively updated documentation, anything with a weekly update cycle — this maintenance burden is real and adds up fast.
Microsoft's GraphRAG: What It Actually Does
In 2024, Microsoft Research published the GraphRAG paper and it got a lot of attention. I dug into both the paper and the open-source implementation. Here's what I actually think about it.
The core insight is correct and valuable: for questions that require understanding the overall themes or structure of a large document set, vector search fails because no single chunk encodes the big picture. GraphRAG builds a graph, runs community detection (using the Leiden algorithm) to cluster connected entities, generates LLM summaries for each community, and stores those summaries as a separate retrieval layer.
When you ask a global question like "what are the main concerns raised across all these incident reports?", GraphRAG can answer using the community summaries. A standard RAG system will retrieve whatever chunks are most similar to "incident report concerns" and give you a partial, context-limited answer.
Here's my honest take after using it: it works extremely well for global, thematic questions, and is complete overkill for everything else.
The indexing is expensive (figure 3–5x the cost of standard embedding-based indexing). The local retrieval mode — for specific factual questions — is not significantly better than hybrid vector search. And the complexity of the setup is non-trivial.
If your use case involves a large, relatively static corpus and users regularly ask broad questions about the entire corpus, GraphRAG is worth it. If your users mostly ask specific questions about specific topics, standard RAG with a good reranker will serve you better at a fraction of the cost.
What the Hybrid Architecture Actually Looks Like
After all of this, what I actually run now for production systems is a hybrid:
- Vector search handles the majority of queries — specific questions, open-ended exploration, anything where semantic similarity is the right signal
- Knowledge graph handles relational queries — "who owns X", "what changed after Y", "what is the connection between A and B"
- Query routing — a lightweight classifier that looks at the incoming query and decides which retrieval path to use
The routing is simpler than it sounds. Questions with relational language ("who", "which team", "what is the relationship", "changed after") go to the graph. Everything else goes to vector search. A small LLM call or even a regex-based heuristic handles 90% of cases correctly.
This approach means you're not paying the graph's maintenance cost for every query — only the ones that actually need it.
What I'd Tell Someone Starting Out
Don't start with a knowledge graph. I say this having built one.
Start with vector RAG. Get it working, get real users using it, and watch where it fails. You will see patterns. If you're getting complaints about relational questions — "it can't tell me who owns what", "it doesn't know how X connects to Y" — that's when you introduce a graph for those specific query types.
The technologies are not in competition. Vectors are excellent at what they do. Knowledge graphs are excellent at what they do. The mistake is expecting one to replace the other.
When I talk to teams who've decided to build a knowledge graph before shipping anything, they almost always end up with a half-finished system that handles neither retrieval mode well. The teams who get it right usually started simple, measured failure, and added structure only where the evidence said they needed it.
Final Thoughts
Vectors store meaning. Graphs store structure. You need both.
The question your retrieval system keeps getting wrong is telling you something. If it returns relevant chunks that don't actually answer the question, you probably have a chunking or retrieval quality problem. If it returns correct facts that don't connect into a coherent answer, you have a structural problem — and that's what knowledge graphs exist to solve.
The entity resolution headaches are real. The indexing cost is real. The maintenance burden is real. Go in with eyes open.
But when you ask a system "who is responsible for this system, and who was responsible before they were?" and it traverses the graph and gives you a precise, traceable answer — you understand immediately why graphs matter. That's something no amount of vector similarity will give you.